

Model March Madness (Part 1)
64 top LLMs compete in a tournament to see who comes out on top!


March Madness is upon us, and as great as college basketball is, I know almost nothing about it. So, let’s replace ballers with models. NCAA with LLM. In this edition of The AI Loop, 64 of today’s highest performance models go head-to-head to see which will be crowned the champion of Model March Madness 2026.
I’ll get into the highly scientific (not really) methodology below. But as is always the case with analyses like these, a lot of it is subjective. I get to decide the criteria, how important they are, and how to score each model based on them. You might have a totally different opinion about how to evaluate this stuff. And to that I say, “You think you’re better than me??”
In any case, at the end of this article, I’m alley-ooping you an HTML file of the interactive bracket so you can do your own analysis and pick your own winner.
With that, let’s get into it!

The Competitors
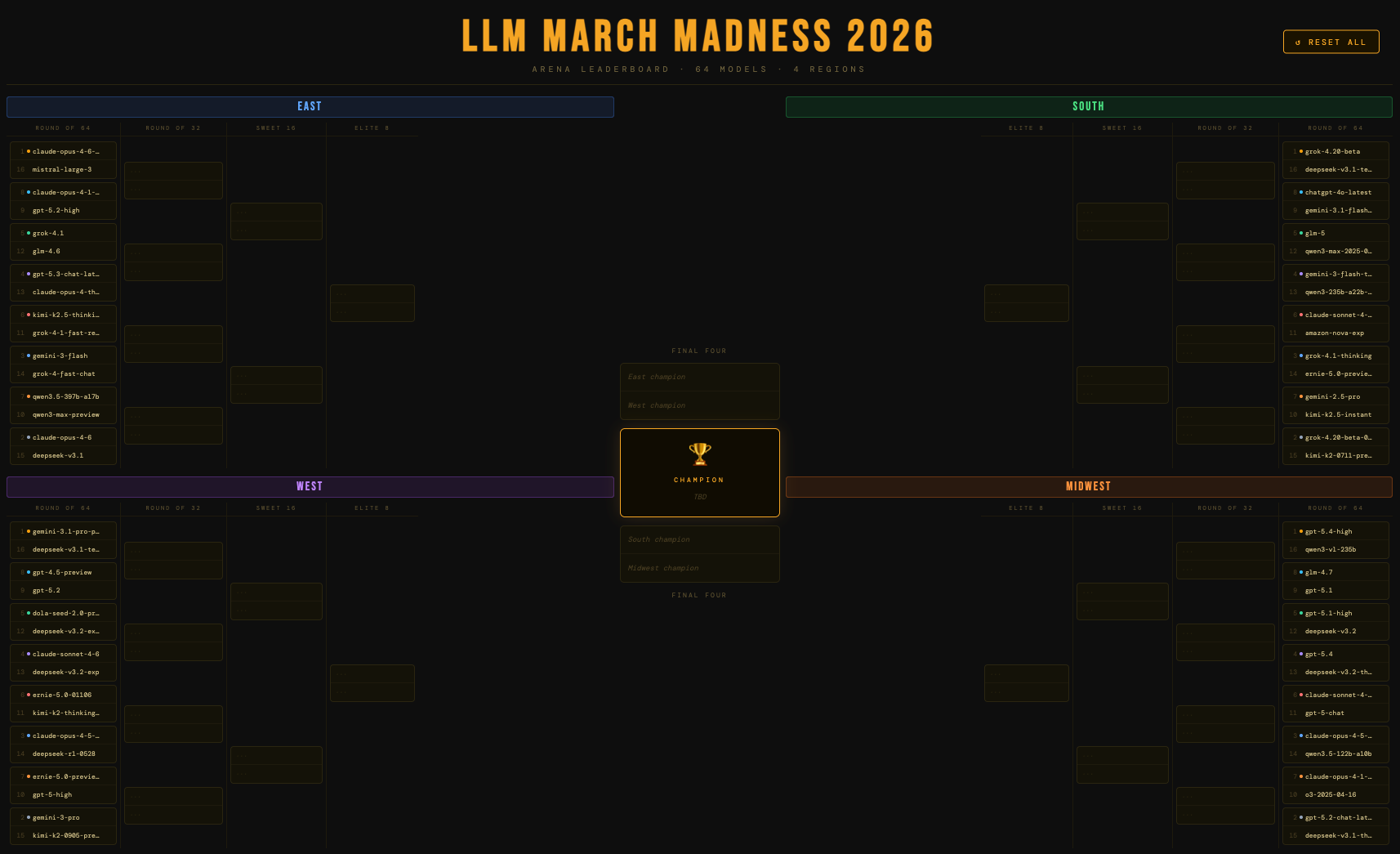
64 models. Four regions. One champion.
To build the field, I pulled the top 64 models from Arena.ai’s leaderboard, which is arguably the most credible ranking system we have right now for comparing LLMs. Rather than relying on cherry-picked benchmarks from the labs themselves, Arena.ai uses over 5 million real human preference votes from side-by-side model comparisons. Models get scored using a format like chess’s ELO system, where defeating higher-ranked competitors earns more points and losing to lower-ranked models costs more points.
The 64 models were randomly divided into four regions (East, West, South, and Midwest) and seeded 1 through 16 within each region based on their overall Arena.ai ranking. I also made sure each top-seeded model came from a different provider. More fun that way.
Notable snubs
Potentially the most glaring omission from the field? Meta’s Llama models. Since releasing Llama 4 back in April 2025, Meta has been slow to share anything noteworthy enough to find itself in the top 64 as of this analysis. On top of that, last year, Meta was accused of a “bait-and-switch” to improve its ranking on arena.ai.
Other notable absences include Cohere, Microsoft’s Phi, AI21, and most of the smaller open-weight models.
The field we do have is stacked:
Anthropic (10 models)
Google (6 models)
OpenAI (13 models)
xAI (6 models)
DeepSeek (9 models)
Alibaba (6 models)
Moonshot AI (5 models)
Zhipu AI (3 models)
Baidu (3 models)
Mistral, Amazon, and ByteDance (1 model each)
If the bracket is missing something egregious, I’d kindly like to point your outrage to arena.ai 😀
The Methodology
Every model in the bracket was scored on three criteria, each weighted differently. The total score determines who advances in each matchup. Simple enough. Here’s how the weights break down:
Benchmark Performance
(weighted 50%)
This is the raw capability score. I looked at performance across coding benchmarks (SWE-bench Verified), reasoning benchmarks (GPQA Diamond), and overall Arena.ai ELO as a sanity check. Coding and expert reasoning benchmarks were especially helpful.
Real-Life Utility
(weighted 30%)
This is the “can I actually ship with this today” score. It covers API availability, pricing per million tokens, latency, tool reliability, and whether the model is GA or still in preview/beta. That last point matters more than people give it credit for. A model without a stable API, an SLA, or published benchmarks is a model you can’t responsibly put in a production. Several models took meaningful hits here for still being in preview at the time of writing, including some high seeds that benchmark beautifully but aren’t production-ready yet.
Versatility
(weighted 20%)
This covers use case range. How well does the model perform across coding, reasoning, long-context analysis, and multimodal inputs? Context window size, native support for vision and audio, and whether the model handles different task types consistently all factor in here.
With all that out of the way, let’s play ball!

Round of 64: First Blood
In a field this stacked, you’d expect chalk (i.e., the favored seeds winning) to mostly hold in the first round. And for the most part, it did. Top seeds advanced, bottom seeds went home. But a few interesting results are worth calling out.
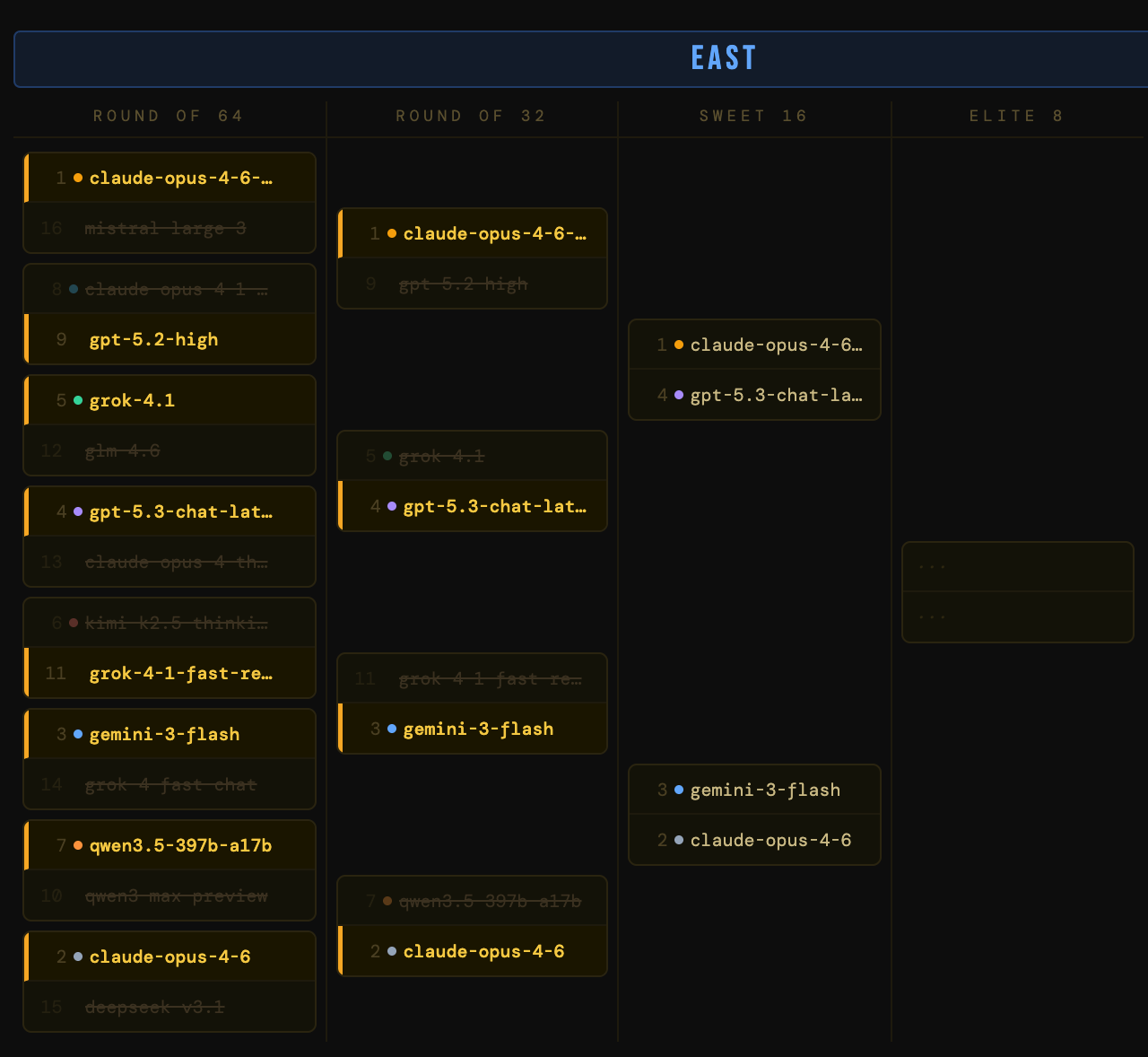
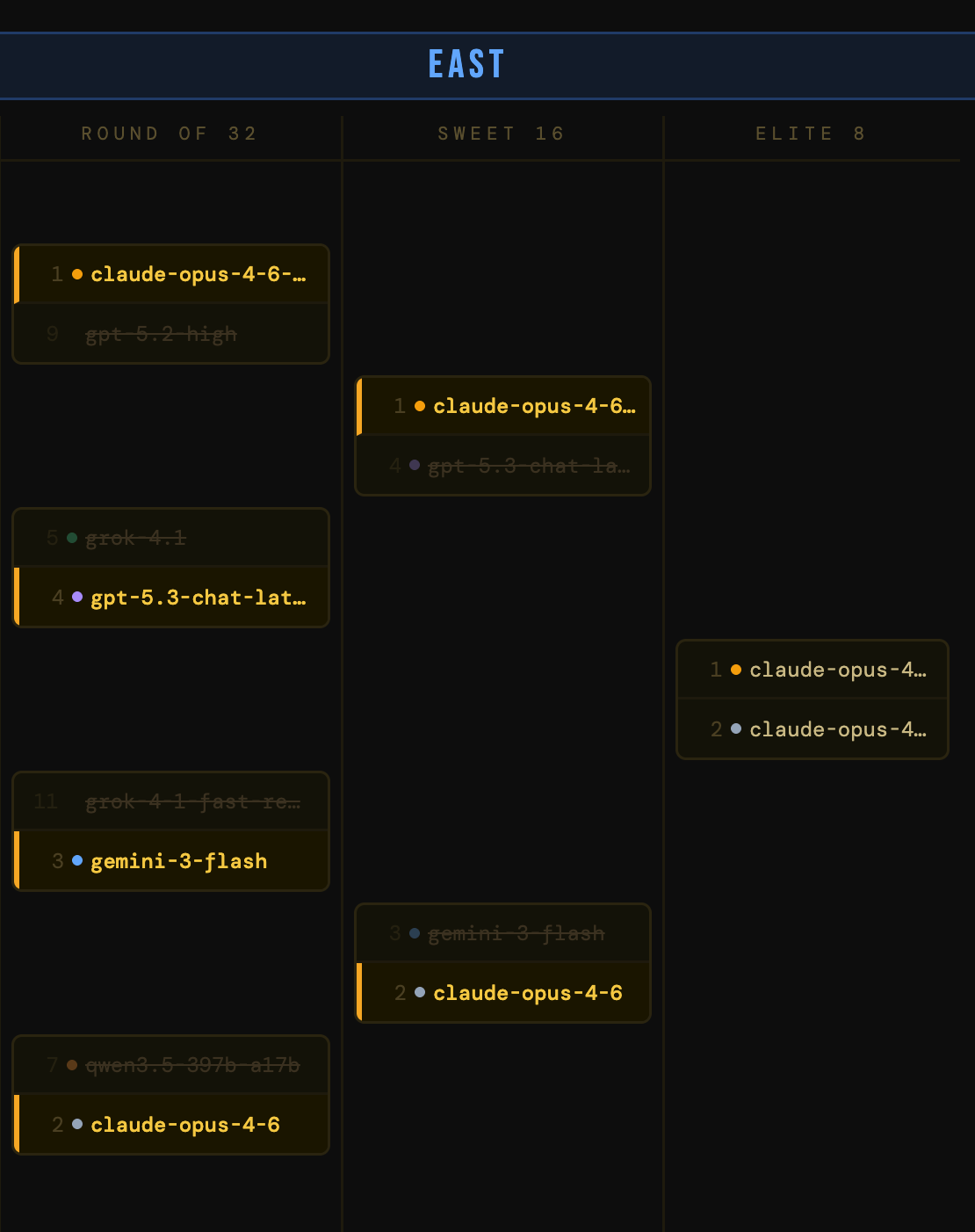
The East
The most well-behaved region. The top seeds persevered, naturally: claude-opus-4-6 and claude-opus-4-6-thinking both cruised through with scary scores across the board, gpt-5.3-chat-latest and grok-4.1 handled their business, too.
But the 8-9 matchup delivered our first upset (i.e., when a lower seed beats a higher seed): gpt-5.2-high knocked out claude-opus-4-1-20250805, the older Claude model simply couldn’t keep up on the utility side of the ledger (a theme you’ll see repeat throughout this bracket).
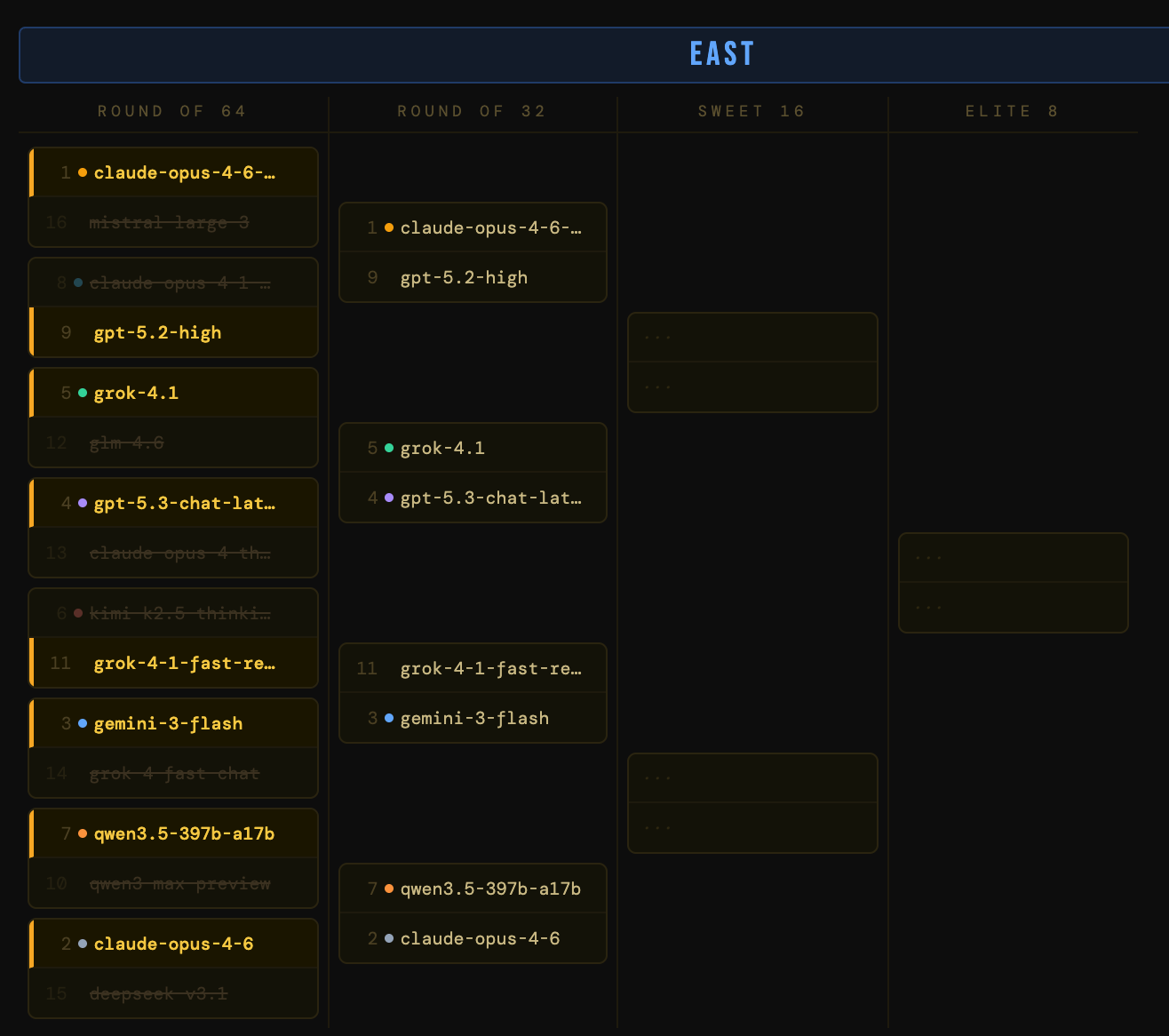
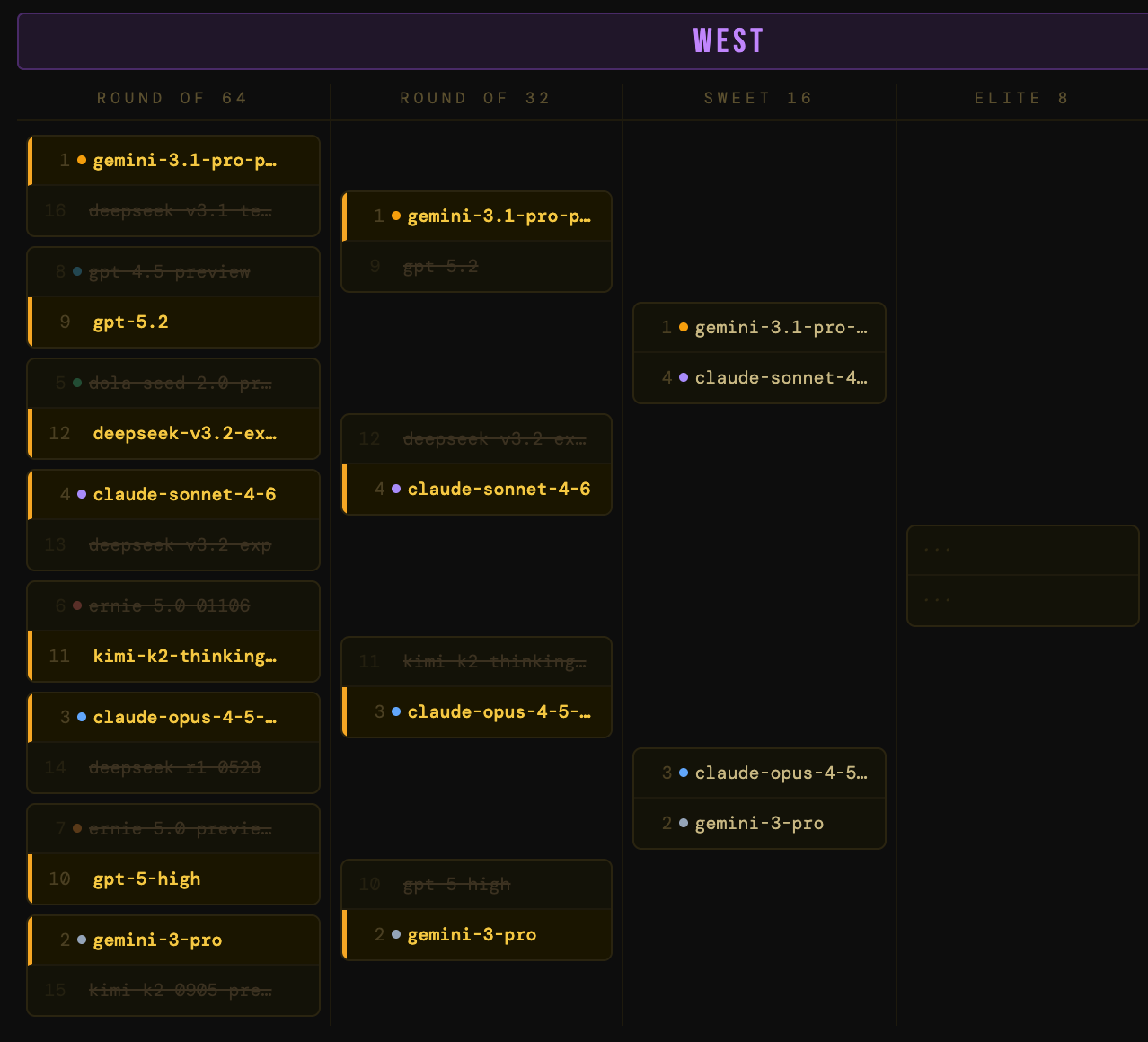
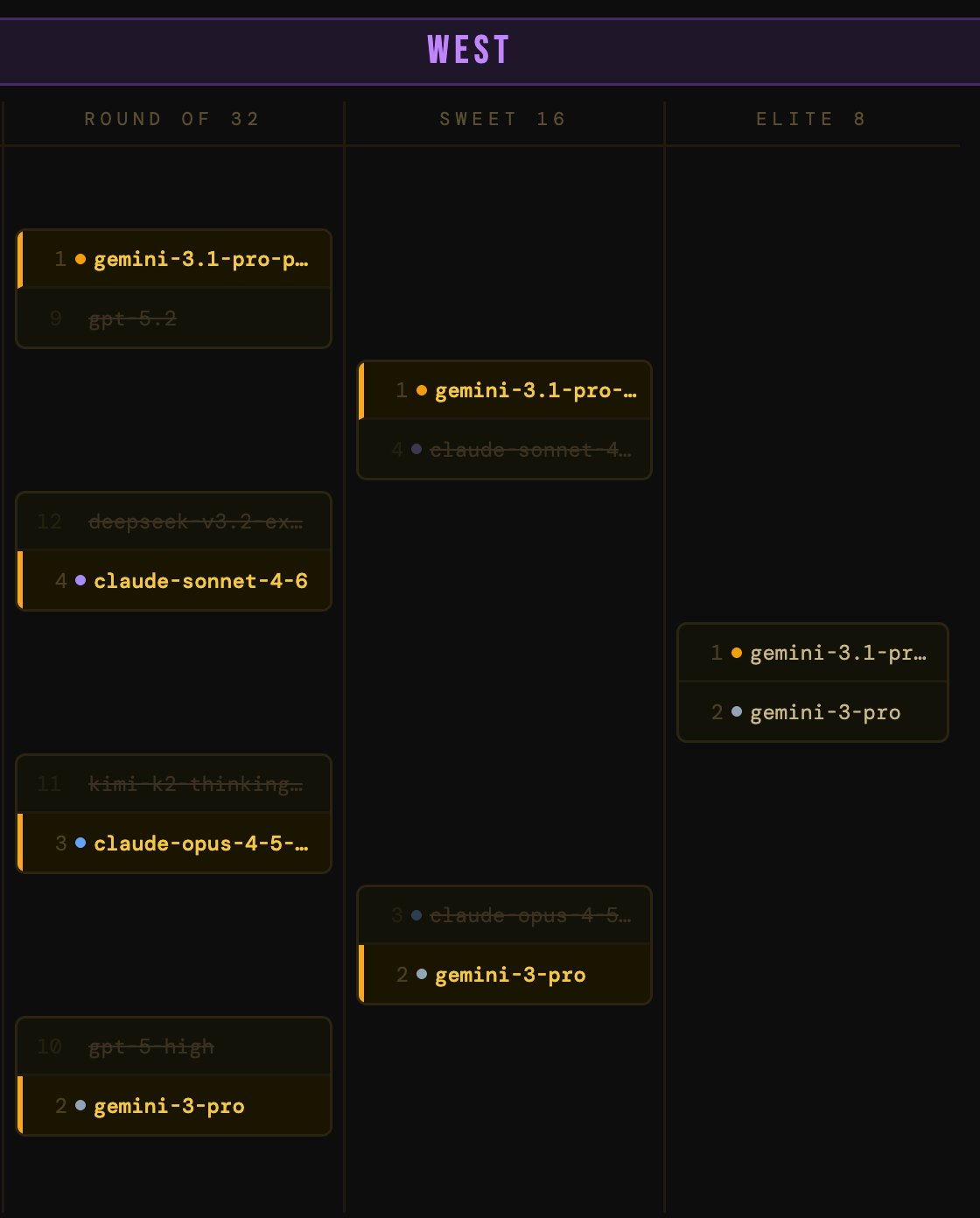
The West
Where things got spicy early. Two upsets in the same region in the first round: dola-seed-2.0-preview (a questionable 5-seed from ByteDance) got bounced immediately by deepseek-v3.2-exp-thinking. The 12-over-5 classic March Madness upset came down to utility – the dola model is in preview (lower utility) while the deepseek model is open-weight (higher utility).
Meanwhile, ERNIE models are a case study in what happens when benchmark performance doesn’t translate into real-world accessibility. Despite their impressive technical specs, both ERNIE models were upset for their lack of utility.
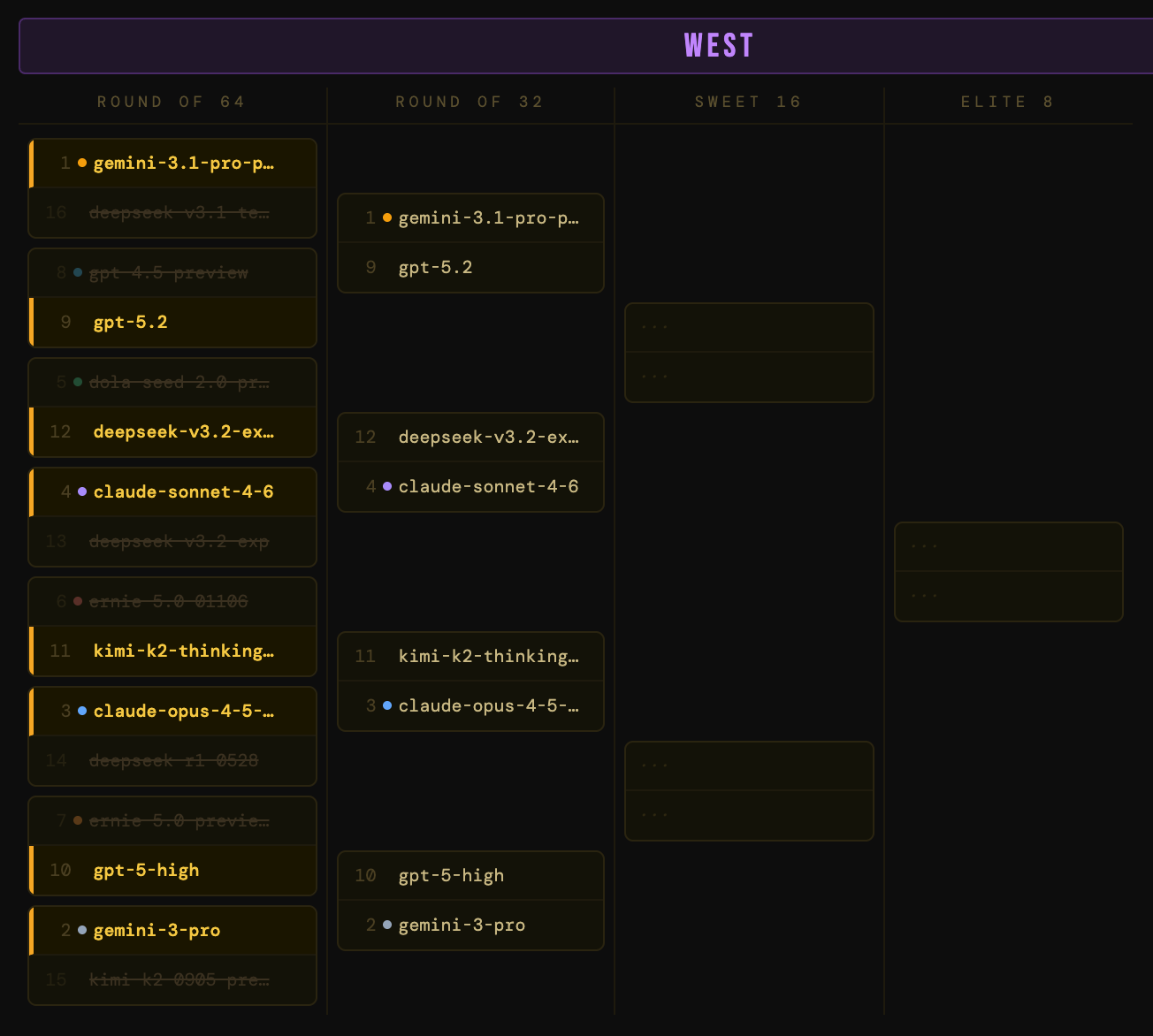
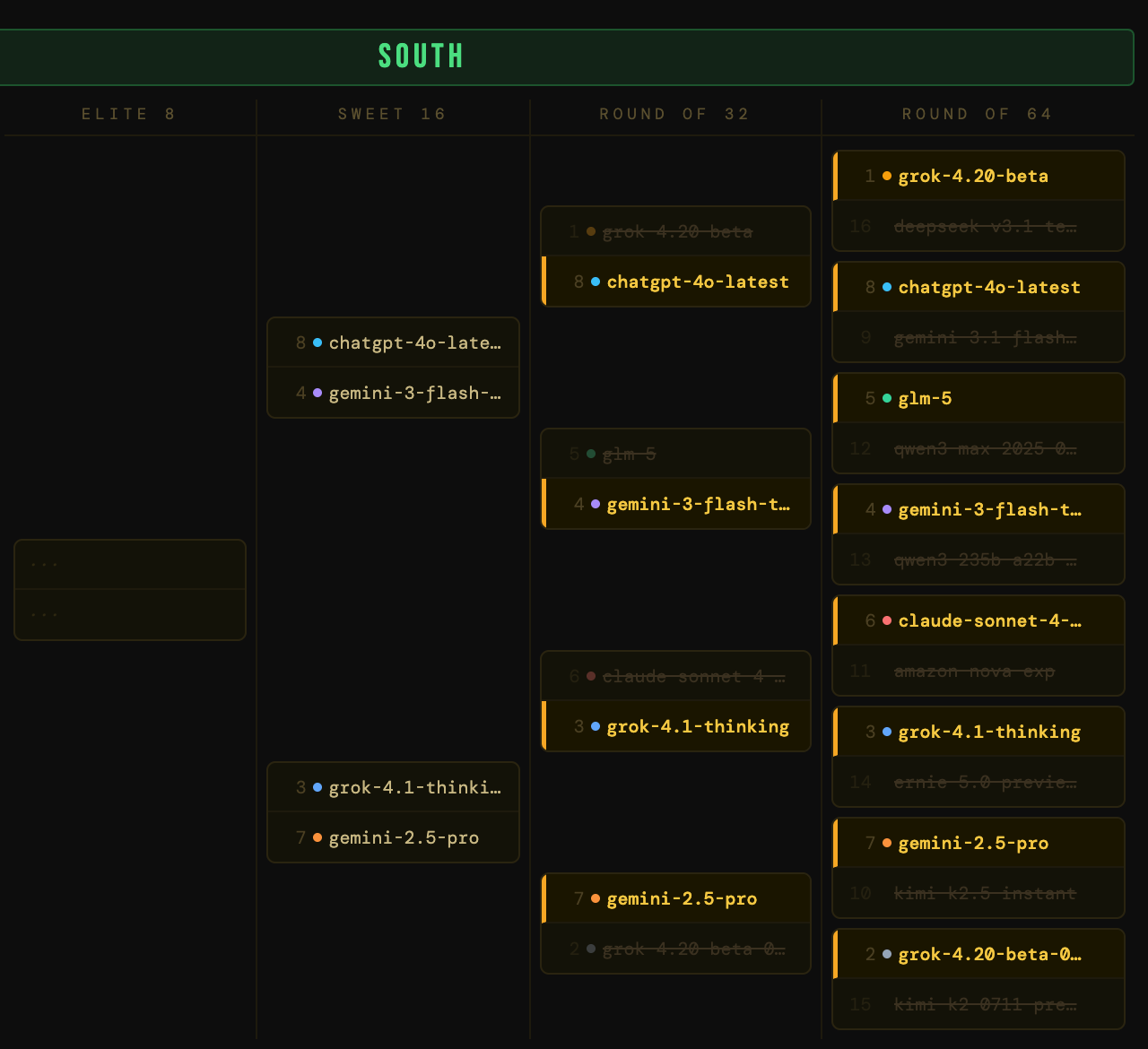
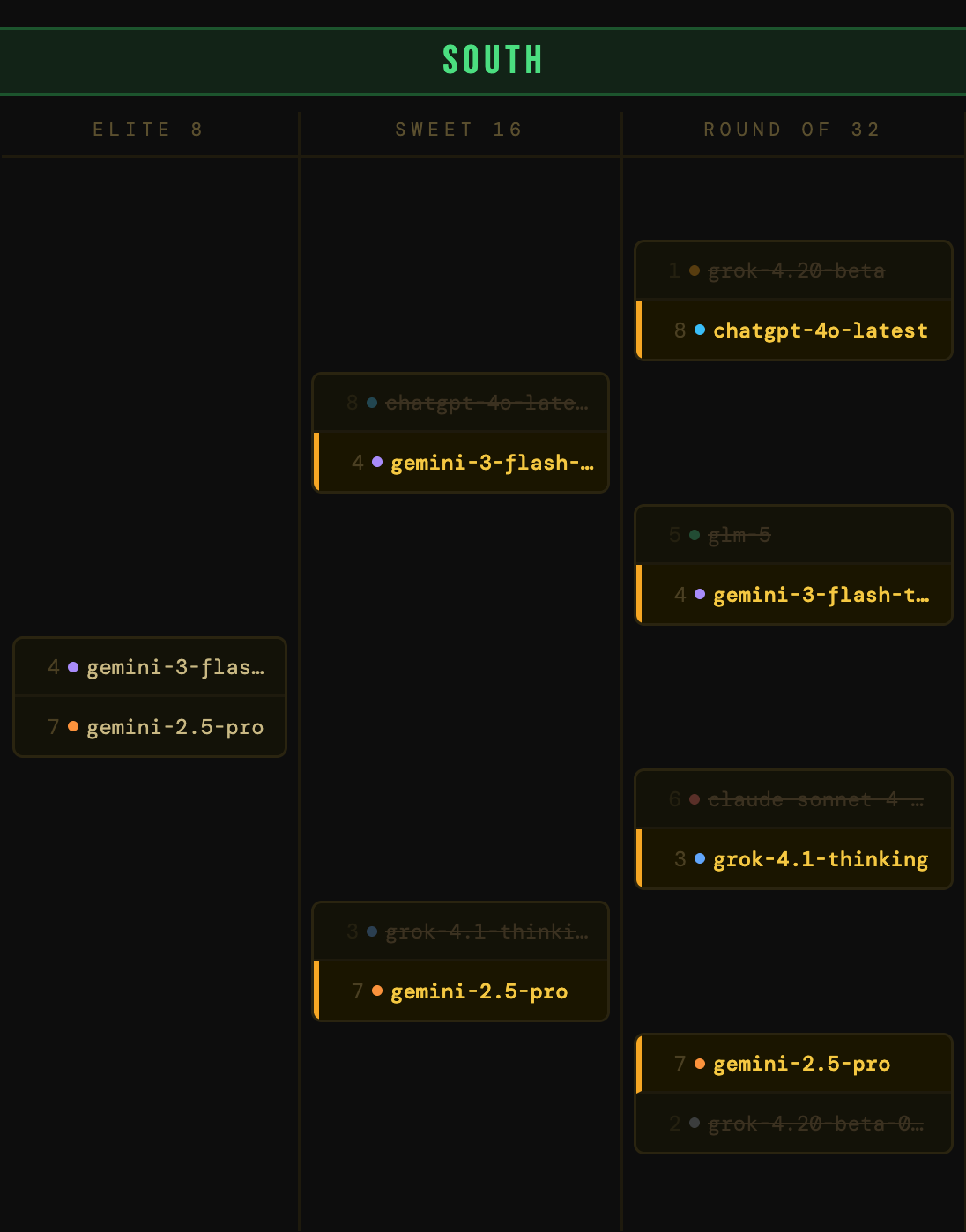
The South
Chalky but some interesting dynamics. The 1-seed grok-4.20-beta survived a tighter-than-expected first round. When you apply a utility penalty for beta status and unverified benchmarks, even a 1-seed starts looking mortal. Also notable: Amazon’s lone model in the fight fell to a Claude Sonnet model. Not so Prime after all.

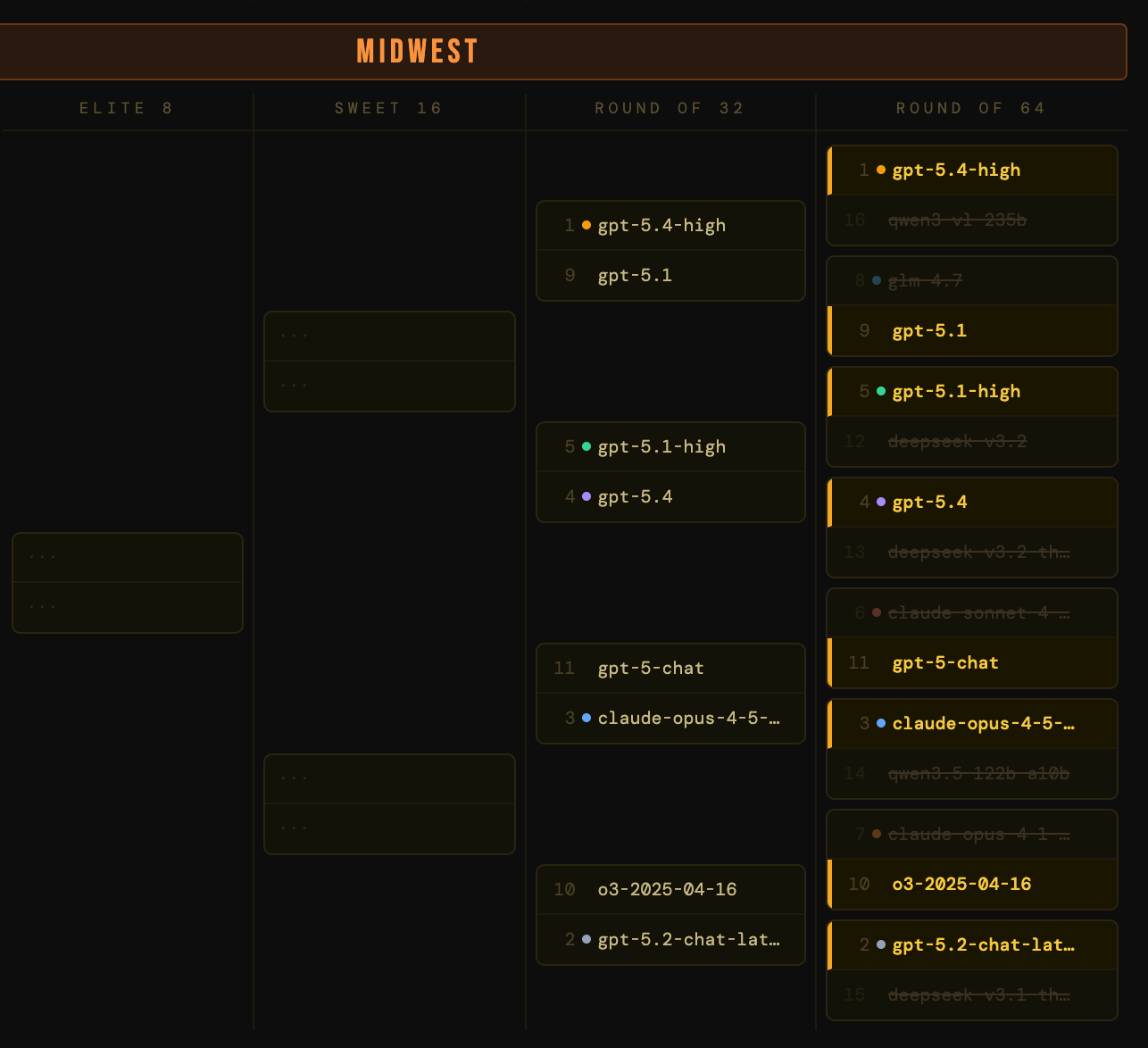
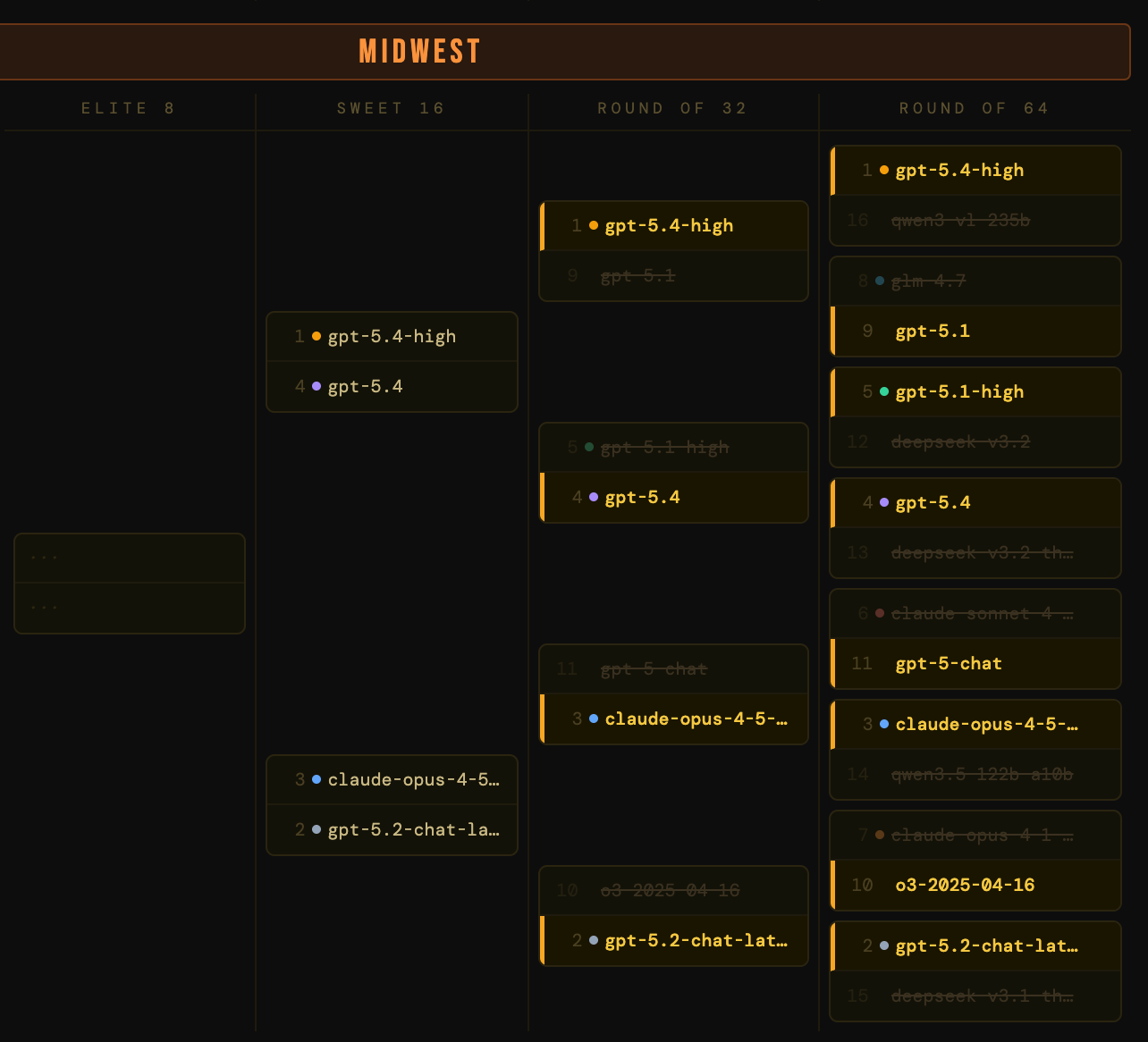
The Midwest
The round’s most electric upsets. The 7-seed, claude-opus-4-1-thinking-16k, lost to o3-2025-04-16 in the 7-10 matchup. Capped reasoning budgets hurt on versatility, and o3 has enough residual credibility to capitalize. And in the 6-11 matchup, gpt-5-chat knocked out claude-sonnet-4-5-thinking-32k, another thinking variant biting the dust early, penalized for the same reasons as its cousins in other regions. I think, therefore I’m eliminated.
Round of 64 Takeaways
Preview models are paying the price for lacking maturity.
Thinking variants with capped budgets are underperforming.
We lost Amazon, Baidu, ByteDance, and Mistral
Round of 32: A 1-Seed Has Fallen
32 models become 16, and the competition heats up. Chalk keeps holding in most places, but some high seeds are showing nasty cracks, including our first 1-seed elimination.
The East
The Claude models of the bracket are dominating. claude-opus-4-6-thinking dusted gpt-5.2-high, and claude-opus-4-6 made quick work of qwen3.5-397b-a17b, a new open-weights model from Alibaba. The East is shaping up as a Claude civil war, with the two Opus 4.6 variants on a collision course.
The West
The chaos continues. deepseek-v3.2-exp-thinking, the 12-seed that earned a shocking win in the first round, ran into claude-sonnet-4-6 and the Cinderella story ended. gemini-3-pro slayed the gpt-5-high dragon by winning versatility points for multimodality and context window. The West is crystallizing into a Google bracket: gemini-3.1-pro-preview and gemini-3-pro are both through.
The South
A 1-seed has fallen! grok-4.20-beta got smoked by chatgpt-4o-latest and its higher-scoring versatility and utility, even though the xAI model won on performance. The 1-seed is an impressive model, but “impressive in beta” doesn’t beat “battle-tested and GA” when you’re scoring for production readiness. Meanwhile, gemini-2.5-pro continued to trample the bracket, knocking out 2-seed grok-4.20-beta-0309-reasoning and becoming the Cinderella story to watch.
Also our first tie! The claude-sonnet-4-5-20250929 vs grok-4.1-thinking matchup ended in a dead tie on total score. We break ties on benchmark performance alone, and based on that, grok-4.1-thinking squeaks through. I don’t make the rules…oh wait, I do.
The Midwest
Altman’s Angels. gpt-5.4 and gpt-5.4-high both advanced, setting up an intra-OpenAI Sweet 16 matchup. gpt-5.2-chat-latest rolled through o3-2025-04-16, which had punched above its weight in the first round but ran out of steam against a more current model.
Round of 32 Takeaways
The field is down to 16 models that all have legitimate claims to being among the best available right now. The pretenders are gone.
This round reminds me how close the frontier really is. In real life, picking a model at this level starts to be more about the context in which you want to use it.
We lost Alibaba, DeepSeek, Moonshot AI, and Zhipu AI
Sweet 16: The Real Contenders
Sixteen models. Two matchups per region. By this point the bracket has done its job of weeding out the preview models that couldn’t back up their seeding, the thinking variants that burned too many tokens for too little payoff, and the regionally-inaccessible models that score well in a lab but poorly in a production environment.
What’s left is a fascinating set of matchups that tell a real story about the state of frontier AI in 2026.
The East
It’s Claude against the world. claude-opus-4-6-thinking edged out gpt-5.3-chat-latest in a close matchup. gpt-5.3 is a strong, well-rounded model with excellent production credentials, but the Claude model’s benchmark ceiling is simply higher. On the other side, claude-opus-4-6 dispatched gemini-3-flash, ending the story for a model with elite utility and cost-efficiency.
The East final is set: claude-opus-4-6-thinking vs claude-opus-4-6. Same base model, different operating modes. The question is whether extended thinking justifies its production cost penalty…ooo ahhh!
The West
A Google civil war. gemini-3.1-pro-preview said, “Screw the GA advantage,” and took down claude-sonnet-4-6 with its benchmark dominance. And gemini-3-pro handled claude-opus-4-5-thinking-32k on the other side.
So the West final is a pure Google showdown: gemini-3.1-pro-preview vs gemini-3-pro. Can a performance leap justify the production instability?
The South
The king killer is dead. After knocking out a 1-seed, chatgpt-4o-latest fell narrowly to gemini-3-flash-thinking in a tie-breaker! Call it a buzzer beater. On the other side, gemini-2.5-pro continued its dominant run through the South, dispatching grok-4.1-thinking. The 7-seed has now beaten three higher seeds in a row. A GA model with strong benchmarks, excellent pricing, and production maturity.
The South final: gemini-3-flash-thinking vs gemini-2.5-pro. Google-on-Google again!
The Midwest
OpenAI drama. gpt-5.4 (the standard variant) knocked out gpt-5.4-high in the closest matchup of the round. This is the same dynamic we explored with Claude’s thinking variants: the “high reasoning” version burns more tokens, carries more cost unpredictability, and for this scoring system, that utility penalty is enough to tip a razor-thin matchup. On the other side, gpt-5.2-chat-latest outperformed claude-opus-4-5-20251101.
The Midwest final: gpt-5.4 vs gpt-5.2-chat-latest. Two OpenAI models, one generation apart. The question is whether the newer model’s improvements justify its higher price point.

Sweet 16 Takeaways
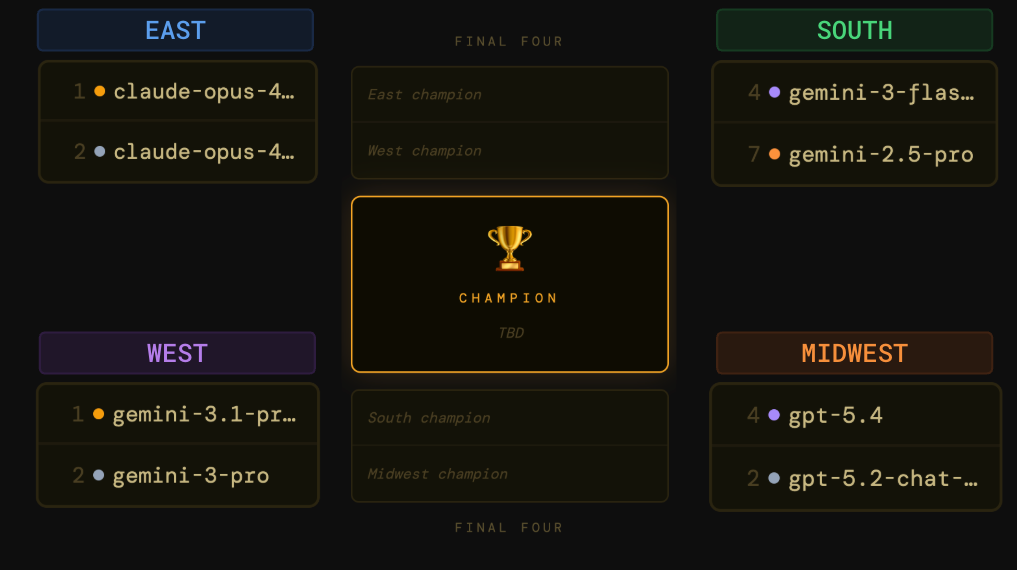
Four regions, four intra-lab matchups for the Elite 8!
The bracket is telling a clear story: the labs that have been doing this the longest, with the most mature deployment infrastructure, are the ones still standing.
We lost xAI.
The Stage Is Set For Part 2
And that’s your Sweet 16. We started with 64 models and we’re down to the Elite 8: Anthropic (2 models), Google (4 models), and OpenAI (2 models). We’ll crown a champion in Part 2 of Model March Madness.
Before we get there, a few things to take away from Part 1.
The preview penalty killed top contenders.
Some of the most technically impressive models in this bracket (e.g., grok-4.20-beta, gemini-3-flash-thinking, gemini-3.1-pro-preview) have benchmark profiles that would make them clear favorites on paper. But AI/ML engineers don’t build production systems on paper. If you can’t depend on the API to stay consistent, if there’s no SLA, if the benchmarks aren’t even officially published yet, that’s a reliability cost. The models that survived this far mostly did so by being excellent and shippable.
Thinking variants got spent by their costs at scale.
Extended reasoning modes are genuinely powerful for hard problems. But they’re not free – in tokens, in latency, or in cost predictability. As AI engineers build for scale and predictability, peak capability can be traded off for speed and cost.
The AI labs with proven track records are winning.
It’s telling that the models still in contention come from mature providers. Anthropic, Google, and OpenAI have once again proven why they’re in the front of the pack. Other providers, even those with impressive models, are playing catchup on performance, utility, and versatility.
In Part 2, we crown a champion. Who are you rooting for?
Want to play with the bracket yourself? Download the HTML file here.
Hey, we’ve got some announcements!
Union.ai just released Flyte 2
The long-awaited successor to the popular OSS AI orchestrator is now available locally. Try a no-install browser demo and learn about its dynamic, self-healing AI orchestration:
Attend this virtual workshop: Self Healing AI Agents
Hosted by Niels Bantilan, we’ll build AI agents that can take infrastructure as context that allows for them to be self healing from failures or limitations.
RSVP to attend or get the recording